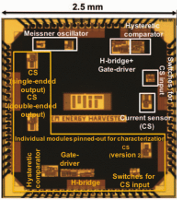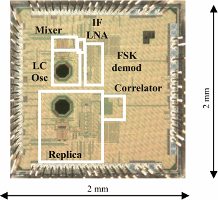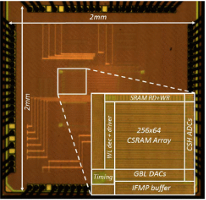
Convolutional neural networks (CNN) provide state-of-the-art results in a wide variety of machine learning (ML) applications, ranging from image classification to speech recognition. However, they are very computationally intensive and require huge amounts of storage. Recent work strived towards reducing the size of the CNNs proposes a binary-weight-network (BWN), where the filter weights are ±1 (with a common scaling factor per filter: α). This leads to a significant reduction in the amount of storage required for the weights, making it possible to store them entirely on-chip. However, in a conventional all-digital implementation, reading the weights and the partial sums from the embedded SRAMs require a lot of data movement per computation, which is energy-hungry. To reduce data-movement, and associated energy, we present an SRAM-embedded convolution architecture, which does not require reading the weights explicitly from the memory. Prior work on embedded ML classifiers have focused on 1b outputs or a small number of output classes, both of which are not sufficient for CNNs. This work uses 7b inputs/outputs, which is sufficient to maintain good accuracy for most of the popular CNNs. The convolution operation is implemented as voltage averaging, since the weights are binary, while the averaging factor (1/N) implements the weight-coefficient α (with a new scaling factor, M, implemented off-chip).